
In this tutorial we will learn, step by step, how to partition Zabbix database (history and trends tables) on MySQL or MariaDB using partitioning script.
Zabbix gathers data from hosts and stores them in database using history and trends tables. Zabbix history keeps raw data (each value that Zabbix has collected) and trends stores consolidated hourly data that is averaged as min,avg, and max.
Zabbix’s housekeeping process is responsible for deleting old trend and history data. Removing old data from the database using SQL delete query can negatively impact database performance. Many of us have received that annoying alarm “Zabbix housekeeper processes more than 75% busy” because of that. Even though database optimization can be helpful (read more about it in this post), at some point, you will hit a brick wall regarding performance, and you will need to get your hands dirty with partitioning.
That problem can be easily solved with the database partitioning. Partitioning creates tables for each hour or day and drops them when they are not needed anymore. SQL DROP is way more efficient than the DELETE statement.
You can use this tutorial for any Zabbix version after 3.0 (3.2, 3.4, 4.0, 4.2, 4.4, 5.0, 5.2, 5.4, 6.0 etc).
Before we continue please make a backup of the Zabbix database, but if the installation is new than there is no need for backup.
Table of Contents
- Step 1: Download SQL script for partitioning
- Step 2: Create partitioning procedures with the SQL script
- Step 3: Run partitioning procedures automatically
- Step 4: Configure Housekeeping on Zabbix frontend
- Step 5: Change partitioning settings (days for history and trends)
- Step 6: Solution for some common errors
- Step 7: Info about Zabbix partitioning script
Step 1: Download SQL script for partitioning
Download and uncompress SQL script “zbx_db_partitiong.sql” on your database server (use wget or curl tool):
curl -O https://bestmonitoringtools.com/dl/zbx_db_partitiong.tar.gz tar -zxvf zbx_db_partitiong.tar.gz
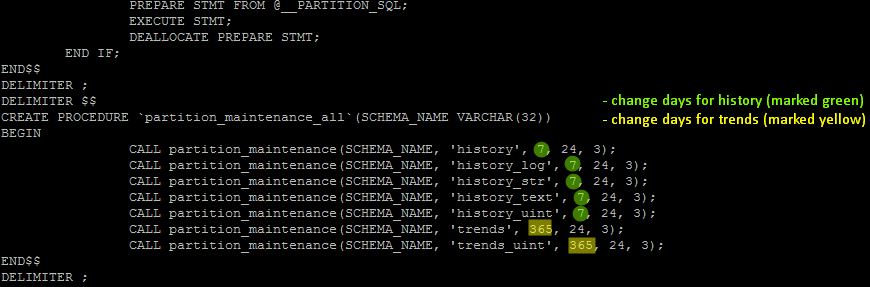
Script “zbx_db_partitiong.sql” is configured to keep 7 days of history data and 365 days of trend data – move to step 2 if those settings are acceptable to you.
However, if you want to change days for trends or history then open file “zbx_db_partitiong.sql“, change settings as shown in the picture below, and save the file.
Step 2: Create partitioning procedures with the SQL script
Syntax for running script is “mysql -u ‘<db_username>’ -p'<db_password>’ <zb_database_name> < zbx_db_partitiong.sql“.
Now, run it with your Zabbix database name, username , and password to create partitioning procedures:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix < zbx_db_partitiong.sql
Script will create MySQL partitioning procedures very quickly on the new Zabbix installation, but on large databases, this may last for hours.
Step 3: Run partitioning procedures automatically
We’ve created partitioning procedures, but they don’t do anything until we run them!
This step is the most important because the partitions must be deleted and created regularly (every day) using partitioning procedures!
Don’t worry, you don’t have to do that manually. We can use two tools for such tasks: MySQL event scheduler or Crontab – choose whatever you prefer.
Be careful when configuring MySQL event scheduler or Crontab. Zabbix will stop collecting data if you misconfigure them! You will notice that by the empty graphs and the error “[Z3005] query failed: [1526] Table has no partition for value ..” in the Zabbix log file.
Option 1: Manage partitions automatically using MySQL event scheduler (recommended)
By default, the MySQL event scheduler is disabled. You need to enable it by setting “event_scheduler=ON” in the MySQL configuration file just after the “[mysqld]” line.
[mysqld] event_scheduler = ON
Don’t know where that file is located? If you used my tutorial for installing and optimizing Zabbix, then the MySQL configuration file (10_my_tweaks.cnf) should be located at “/etc/mysql/mariadb.conf.d/” or “/etc/my.cnf.d/“, otherwise try to search for it with the command:
sudo grep --include=*.cnf -irl / -e "\[mysqld\]"
Once you have made the changes restart your MySQL server for the setting to take effect!
sudo systemctl restart mysql
Nice! MySQL event scheduler should be enabled, let’s check that with the command:
root@dbserver:~ $ mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "SHOW VARIABLES LIKE 'event_scheduler';" +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | event_scheduler | ON | +-----------------+-------+
Now we can create an event that will run procedure “partition_maintenance_all” every 12 hours.
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CREATE EVENT zbx_partitioning ON SCHEDULE EVERY 12 HOUR DO CALL partition_maintenance_all('zabbix');"
After 12 hours, check to see if the event has been executed successfully using the command below.
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "SELECT * FROM INFORMATION_SCHEMA.events\G"
EVENT_CATALOG: def
...
CREATED: 2020-10-24 11:01:07
LAST_ALTERED: 2020-10-24 11:01:07
LAST_EXECUTED: 2020-10-24 11:43:07
...
Option 2: Manage partitions automatically using Crontab
Crontab is a good alternative if you are unable to use the MySQL event scheduler. Open crontab file with the command “sudo crontab -e” and add a job for partitioning Zabbix MySQL database (every day at 03:30 AM) by adding this line anywhere in the file:
30 03 * * * /usr/bin/mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all('zabbix');" > /tmp/CronDBpartitiong.log 2>&1
Save and close file.
Cron will execute patitioning every day (drop old tables and create new ones) and log everything in file “/tmp/CronDBpartitiong.log“.
However, if you are impatient then run command immediately from the terminal:
root@dbserver:~ $ mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all('zabbix');" +-----------------------------------------------------------+ | msg | +-----------------------------------------------------------+ | partition_create(zabbix,history,p201910150000,1571180400) | +-----------------------------------------------------------+ +-----------------------------------------------------------+ ...etc.
and check the partitioning status afterward:
root@dbserver:~ $ mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "show create table history\G" Table: history Create Table: CREATE TABLE history ( itemid bigint(20) unsigned NOT NULL, clock int(11) NOT NULL DEFAULT '0', value double(16,4) NOT NULL DEFAULT '0.0000', ns int(11) NOT NULL DEFAULT '0', KEY history_1 (itemid,clock) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin /*!50100 PARTITION BY RANGE (clock) (PARTITION p201910140000 VALUES LESS THAN (1571094000) ENGINE = InnoDB, PARTITION p201910150000 VALUES LESS THAN (1571180400) ENGINE = InnoDB, PARTITION p201910160000 VALUES LESS THAN (1571266800) ENGINE = InnoDB) */
As you can see in the outputs, we have created 3 partitions for the history table.
Step 4: Configure Housekeeping on Zabbix frontend
Configure housekeeping on Zabbix frontend as shown in the picture below.
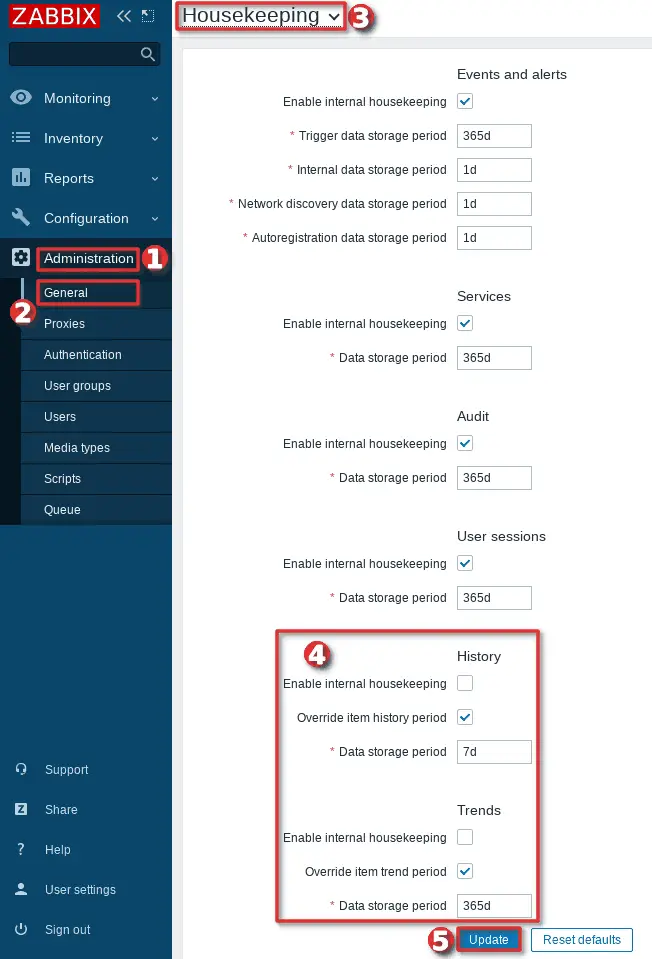
If the picture is not self-explanatory, here are the steps for configuring housekeeping on Zabbix frontend:
- navigate to “Housekeeping” section: “Administration” → “General” → “Housekeeping“;
- remove the checkmark from “Enable internal housekeeping” under History and Trends section;
- put a checkmark on “Override item trend period” under History and Trends section;
- define days for “data storage period” for trends and history under the History and Trends section (must be the same as the days configured in database partitioning – that should be 7 days for history and 365 days for trends if you haven’t changed the default settings in the script);
- click the “Update” button.
And you are done! Keep in mind that the partitioning will delete history and trend tables according to what you have configured in the partitioning procedure. For example, if you have configured to keep 7 days of history, partitioning will start deleting history on the 8th day. After that, it will delete one history table every day so that the database always has 7 days of the history data. The same goes for the trend data, if you configured to keep 365 days of the trend data, only after 365 days it will start deleting old trend tables.
CONGRATULATIONS!
You have successfully partitioned MySQL tables on the Zabbix database!
No need to change anything else as other steps are optional.
CONTINUE TO LEARN MORE:
How to change partitioning settings
Read more about partitioning procedures that are used in the script.
Step 5: Change partitioning settings (days for history and trends)
Sometimes it may happen that you initially set too many days for history and trends for the Zabbix database, so the disk space fills up too quickly. Or the opposite happens, you didn’t configure enough days for history or trends. What to do then?
You don’t need to run the script again, just create a new procedure that you will run instead of the old one.
a) Create a new partitioning procedure
Connect to the MySQL/MariaDB server:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix
Create a new procedure but change the number of days for trends and history according to your needs, I will set 30 days for history and 400 days for trends:
DELIMITER $$ CREATE PROCEDURE partition_maintenance_all_30and400(SCHEMA_NAME VARCHAR(32)) BEGIN CALL partition_maintenance(SCHEMA_NAME, 'history', 30, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_log', 30, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_str', 30, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_text', 30, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 30, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'trends', 400, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 400, 24, 3); END$$ DELIMITER ;
b) Update MySQL event scheduler or Crontab
We have created the partitioning procedure in the previous step, but it is not active yet! Now we must replace the old procedure with the new one that will delete and add partitions regularly. Choose one of the two options below depending on what you have configured on your Zabbix instance.
Option 1: Update MySQL event scheduler
If you created the event scheduler following this tutorial, then use this command to replace the old procedure with the new one.
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "ALTER EVENT zbx_partitioning ON SCHEDULE EVERY 12 HOUR DO CALL partition_maintenance_all_30and400('zabbix');"
Option 2: Update Crontab
For those using Crontab, open crontab file with the command “sudo crontab -e“, comment out the the old procedure job, and add a new one
# old procedure, still exists in the database so it can be used if needed
# 30 03 * * * /usr/bin/mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all('zabbix');" > /tmp/CronDBpartitiong.log 2>&1
30 03 * * * /usr/bin/mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CALL partition_maintenance_all_30and400('zabbix');" > /tmp/CronDBpartitiong.log 2>&1
Save your changes and exit the Crontab.
Step 6: Solution for some common errors
Duplicate partition name
If you have a different time setting on MySQL compared to your Linux OS, you will receive an error regarding duplicate partition names:
ERROR 1517 (HY000) at line 1: Duplicate partition name p202307100000
Check time on MySQL with command “SELECT CURRENT_TIMESTAMP ;” and on OS with command “timedatectl“.
If they are different then set your timezone correctly using this guide, and then restart the MySQL server.
Waiting for table metadata lock (graphs with no data)
The database partitioning commands used in this script modify metadata on the history and trends tables. If another query is holding a metadata lock on those tables, the partitioning script will ‘hang’ and block every other command, including Zabbix queries that insert data into the trend and history tables.
At first, you might think this is a fault of the partitioning script. However, upon closer examination, you will probably find some other application or script that is using Zabbix tables, causing the hang and holding that metadata lock.
My recommendation is to fix that other application or script to release the metadata lock. In the meantime, you can terminate those hanging queries by running this command in the crontab, just before you execute the partitioning script:
/usr/bin/mysql -u'root' -p'MyRootPass2!?' -e "SELECT GROUP_CONCAT(CONCAT('KILL ', id) SEPARATOR ';') AS kill_commands FROM information_schema.processlist WHERE db = 'zabbix' AND user IN ('scriptuser', 'crmapp') AND command = 'Sleep'" | grep -v '^kill_commands$' | /usr/bin/mysql -u'root' -p'MyRootPass2!?'
In my example, the command will terminate any sleeping queries originating from users named ‘scriptuser’ and ‘crmapp’. Alternatively, you can configure it applay to any non-Zabbix users using the following condition: ‘AND user != ‘zabbix’ and removing ” AND user IN (“..” part.
Finding out which user and query are holding the metadata lock is beyond the scope of this discussion. However, the following steps can be taken: Use ‘SHOW FULL PROCESSLIST;’ to check the currently running queries and their statuses. Check for queries with a ‘NULL’ value in the ‘trx_query’ field using the command ‘SELECT * FROM information_schema.INNODB_TRX \G;’. And use the query below to find out details about queries that are in a ‘sleeping’ status:
SELECT performance_schema.threads.PROCESSLIST_ID,performance_schema.threads.THREAD_ID, performance_schema.events_statements_current.SQL_TEXT,information_schema.INNODB_TRX.trx_started FROM performance_schema.threads INNER JOIN information_schema.INNODB_TRX ON performance_schema.threads.PROCESSLIST_ID = information_schema.INNODB_TRX.trx_mysql_thread_id INNER JOIN performance_schema.events_statements_current ON performance_schema.events_statements_current.THREAD_ID = performance_schema.threads.THREAD_ID\G;
Step 7: Info about Zabbix partitioning script
Zabbix partitioning SQL script that is used in this guide contains these partitioning procedures:
DELIMITER $$ CREATE PROCEDURE `partition_create`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int) BEGIN /* SCHEMANAME = The DB schema in which to make changes TABLENAME = The table with partitions to potentially delete PARTITIONNAME = The name of the partition to create */ /* Verify that the partition does not already exist */ DECLARE RETROWS INT; SELECT COUNT(1) INTO RETROWS FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_description >= CLOCK; IF RETROWS = 0 THEN /* 1. Print a message indicating that a partition was created. 2. Create the SQL to create the partition. 3. Execute the SQL from #2. */ SELECT CONCAT( "partition_create(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg; SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' ); PREPARE STMT FROM @sql; EXECUTE STMT; DEALLOCATE PREPARE STMT; END IF; END$$ DELIMITER ; DELIMITER $$ CREATE PROCEDURE `partition_drop`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), DELETE_BELOW_PARTITION_DATE BIGINT) BEGIN /* SCHEMANAME = The DB schema in which to make changes TABLENAME = The table with partitions to potentially delete DELETE_BELOW_PARTITION_DATE = Delete any partitions with names that are dates older than this one (yyyy-mm-dd) */ DECLARE done INT DEFAULT FALSE; DECLARE drop_part_name VARCHAR(16); /* Get a list of all the partitions that are older than the date in DELETE_BELOW_PARTITION_DATE. All partitions are prefixed with a "p", so use SUBSTRING TO get rid of that character. */ DECLARE myCursor CURSOR FOR SELECT partition_name FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND CAST(SUBSTRING(partition_name FROM 2) AS UNSIGNED) < DELETE_BELOW_PARTITION_DATE; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; /* Create the basics for when we need to drop the partition. Also, create @drop_partitions to hold a comma-delimited list of all partitions that should be deleted. */ SET @alter_header = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " DROP PARTITION "); SET @drop_partitions = ""; /* Start looping through all the partitions that are too old. */ OPEN myCursor; read_loop: LOOP FETCH myCursor INTO drop_part_name; IF done THEN LEAVE read_loop; END IF; SET @drop_partitions = IF(@drop_partitions = "", drop_part_name, CONCAT(@drop_partitions, ",", drop_part_name)); END LOOP; IF @drop_partitions != "" THEN /* 1. Build the SQL to drop all the necessary partitions. 2. Run the SQL to drop the partitions. 3. Print out the table partitions that were deleted. */ SET @full_sql = CONCAT(@alter_header, @drop_partitions, ";"); PREPARE STMT FROM @full_sql; EXECUTE STMT; DEALLOCATE PREPARE STMT; SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, @drop_partitions AS `partitions_deleted`; ELSE /* No partitions are being deleted, so print out "N/A" (Not applicable) to indicate that no changes were made. */ SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, "N/A" AS `partitions_deleted`; END IF; END$$ DELIMITER ; DELIMITER $$ CREATE PROCEDURE `partition_maintenance`(SCHEMA_NAME VARCHAR(32), TABLE_NAME VARCHAR(32), KEEP_DATA_DAYS INT, HOURLY_INTERVAL INT, CREATE_NEXT_INTERVALS INT) BEGIN DECLARE OLDER_THAN_PARTITION_DATE VARCHAR(16); DECLARE PARTITION_NAME VARCHAR(16); DECLARE OLD_PARTITION_NAME VARCHAR(16); DECLARE LESS_THAN_TIMESTAMP INT; DECLARE CUR_TIME INT; CALL partition_verify(SCHEMA_NAME, TABLE_NAME, HOURLY_INTERVAL); SET CUR_TIME = UNIX_TIMESTAMP(DATE_FORMAT(NOW(), '%Y-%m-%d 00:00:00')); SET @__interval = 1; create_loop: LOOP IF @__interval > CREATE_NEXT_INTERVALS THEN LEAVE create_loop; END IF; SET LESS_THAN_TIMESTAMP = CUR_TIME + (HOURLY_INTERVAL * @__interval * 3600); SET PARTITION_NAME = FROM_UNIXTIME(CUR_TIME + HOURLY_INTERVAL * (@__interval - 1) * 3600, 'p%Y%m%d%H00'); IF(PARTITION_NAME != OLD_PARTITION_NAME) THEN CALL partition_create(SCHEMA_NAME, TABLE_NAME, PARTITION_NAME, LESS_THAN_TIMESTAMP); END IF; SET @__interval=@__interval+1; SET OLD_PARTITION_NAME = PARTITION_NAME; END LOOP; SET OLDER_THAN_PARTITION_DATE=DATE_FORMAT(DATE_SUB(NOW(), INTERVAL KEEP_DATA_DAYS DAY), '%Y%m%d0000'); CALL partition_drop(SCHEMA_NAME, TABLE_NAME, OLDER_THAN_PARTITION_DATE); END$$ DELIMITER ; DELIMITER $$ CREATE PROCEDURE `partition_verify`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), HOURLYINTERVAL INT(11)) BEGIN DECLARE PARTITION_NAME VARCHAR(16); DECLARE RETROWS INT(11); DECLARE FUTURE_TIMESTAMP TIMESTAMP; /* * Check if any partitions exist for the given SCHEMANAME.TABLENAME. */ SELECT COUNT(1) INTO RETROWS FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_name IS NULL; /* * If partitions do not exist, go ahead and partition the table */ IF RETROWS = 1 THEN /* * Take the current date at 00:00:00 and add HOURLYINTERVAL to it. This is the timestamp below which we will store values. * We begin partitioning based on the beginning of a day. This is because we don't want to generate a random partition * that won't necessarily fall in line with the desired partition naming (ie: if the hour interval is 24 hours, we could * end up creating a partition now named "p201403270600" when all other partitions will be like "p201403280000"). */ SET FUTURE_TIMESTAMP = TIMESTAMPADD(HOUR, HOURLYINTERVAL, CONCAT(CURDATE(), " ", '00:00:00')); SET PARTITION_NAME = DATE_FORMAT(CURDATE(), 'p%Y%m%d%H00'); -- Create the partitioning query SET @__PARTITION_SQL = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " PARTITION BY RANGE(`clock`)"); SET @__PARTITION_SQL = CONCAT(@__PARTITION_SQL, "(PARTITION ", PARTITION_NAME, " VALUES LESS THAN (", UNIX_TIMESTAMP(FUTURE_TIMESTAMP), "));"); -- Run the partitioning query PREPARE STMT FROM @__PARTITION_SQL; EXECUTE STMT; DEALLOCATE PREPARE STMT; END IF; END$$ DELIMITER ; DELIMITER $$ CREATE PROCEDURE `partition_maintenance_all`(SCHEMA_NAME VARCHAR(32)) BEGIN CALL partition_maintenance(SCHEMA_NAME, 'history', 7, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_log', 7, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_str', 7, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_text', 7, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 7, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'trends', 365, 24, 3); CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 365, 24, 3); END$$ DELIMITER ;
Need more information ? Watch this video about MySQL database partitioning for Zabbix.
Thank you for reading.
Hi,
We’re using Zabbix 7.2.2 with a MariaDB 10.5.22 database.
We’ve installed the script as descibed. The partitions are made as expected, but they are not dropped.
What’s going wrong?
Kind regards,
Jaap
After studying the script, I think I had figured out how to do that: change the 4th argument 24 to 24*30=720 to partition trends for every month. Am I right? but I not sure if the 5th need to be changed as well.
CALL partition_maintenance(SCHEMA_NAME, ‘trends’, 365, 720, 3);
CALL partition_maintenance(SCHEMA_NAME, ‘trends_uint’, 365, 720, 3);
Hi,
Zabbix has now been updated to 7.0. Can you update this sql script?
It appears the current partitioning script is not compatible with MySQL 8. I get the following error when trying to deploy it on a fresh install of Zabbix with a MySQL 8 backend:
QL Error [1064] [42000]: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ” at line 3
Hello,
great utility. What you mind making it compatible to a database name with a “-” (dash) in the name?
Thank you.
There seems to be some debate about using an external script vs stored procedures. I’d like to point out one major advantage here.
Stored procedures do not require additional software!
The downsides are that it is not as easy to make a modification to a stored procedure. (Perhaps a future version could use a table that stores the parameters, making it easier for someone to ‘adjust’ it if they found the need.)
A huge downside to using an external script is that you manually have to create the partition tables. This can be time-consuming and error-prone. This SQL script only creates the partition tables from the current day forward. In practice, this really isn’t an issue if you are purging old records in say the 7 days as a default. It might be an issue if you are choosing to keep longer history, however.
Manually executing the script on a “large” history_uint table, approx 20GB took me roughly an hour on a Digital Ocean VM w/ 2 cpu and 4GB ram. (for those wondering how long it takes).
I actually had errors running the command manually due to limited space on the system and had to remove some files to make enough working room on our 80GB disk. (my zone does not support additional storage). So make sure you have free space at least the size of your largest table if you are applying this to an existing database. (In our case we had a history for 365 days!)
The way this procedure works, creating only 3 new partitions should work for most users. I originally decided to modify the event schedule to run every 24 hours but later reverted back to the 12hr intervals as if for some reason it failed to run (such as disk space) it would at least give about 6 tries rather than 3.
I think using the stored procedure is obviously a much nicer solution, and I think that perhaps adding a custom table with the partitioning variables in it might make for a nice “enhancement” for tweaking the settings. (e.g. we keep 90 days history to keep managers happy, then realize you are good with less, and make it easier to adjust with just a simple field modification)
hello i have the problem that when the script runs the zabbix does not collect any data for about 30-45 min and the “Utilization of internal processes” goes to 100%.
Looking forward to hearing from you.
After successfull upgrade to zabbix 6, it seems that the script does not clean disk space as before even if the script has been executed.
In mysql error.log I have found this :
[Warning] [MY-010045] [Server] Event Scheduler: [zabbix@localhost][zabbix.zbx_partitioning] ‘utf8mb3_bin’ is a collation of the deprecated character set UTF8MB3. Please consider using UTF8MB4 with an appropriate collation instead.
database seems corrrect :
mysql> SELECT @@character_set_database, @@collation_database;
+————————–+———————-+
| @@character_set_database | @@collation_database |
+————————–+———————-+
| utf8mb4 | utf8mb4_unicode_520_ci |
+————————–+———————-+
Any idea ?
Hi
It’s a great method and I’ve been using it for over a year now, but I’ve also found a few problems.
If we manage history and trends data in this way, when we delete a host item, its history and trends data record still remains in database table.
So in a scenario where database storage is strictly limited, I want to delete a lot of items to free up storage on a zabbix that’s been running for a long time, we find that this operation doesn’t free up storage space.
Because of the need to free up storage space in time, it’s too late to wait for the data partition was deleted, I can only delete these redundant data records in bulk through sql statements.
So I would like to ask if there is a better way to solve this kind of problem?
By the way, my data partitioning strategy is usually one year of history data and six months of trend data. Normally I would plan the database storage space to support such a long period of data storage, this storage capacity is usually not easily increased once it has been planned.During the run, the number of items exceeded the expectation, so there was a case of deleting the extra items to free up storage space.
Hi friend, zabbix partition tool script compressed package is damaged and can’t be used. Please give me another one that can be used. Thank you.
There was a mistake in the tutorial, but I have now corrected it. Please make sure to use HTTPS instead of HTTP.
Hi,
in V6.0.12 one more checkbox is available under Administration → General → Housekeeping.
It’s name is “* Service data storace period”.
My question is, if it is also a seperate table which is not oncluded in this database fragmentation script.
Looking forward to hearing from you.
This script only handles the history and trends tables. For everything else, use the Zabbix housekeeping service by checking the box on the Housekeeping GUI.
Wonderful ! i am going to test it.
Hi, thanks for this “How to”
I’ve got a question, i want to clean the auditlog table so i add the line:
CALL partition_maintenance(SCHEMA_NAME, ‘auditlog’, 90, 24, 3);
But it does not seems to work .. do you know how to clean this table ? It’s huge !
Partitioning cleans just history and trends tables. Let the Zabbix clean the audit log with housekeeping, just change housekeeping settings under administration.
Or delete everything from auditlog table with “TRUNCATE TABLE auditlog;”
Do you see any problems upgrading from 5.0LTS (that has this implemented) to 6.0LTS? Thanks again for this article!
Hi!
Is this solution working in Zabbix 6.0 ?
BR
Yes
This is awesome work. Do you know if partitioning will affect future upgrades of the Zabbix server or DB?
No, it won’t. I upgraded Zabbix multiple times with no problems.
thanks for the great post!
This is exactly what I was looking for, and I’m already looking forward to improvement.
Best Regards,
Hi!
Thanks for your tutorial!
But I have a problem.
When the partitioning arrives to my history_uint and trends_uint tables, I have the problem “Table has no partition for value XXXXXXXX”.
I am on MariaDB 10.14.2 and Zabbix 5.6.
Thank you!
Hi,
I have explained that error in the section “Step 3: Run partitioning procedures automatically”
Regards
Hi,
I’ve tried your solution with store proc. Currently, I’m facing an issue when I want to launch the procedure. There is a message :
ERROR 1503 (HY000) at line 1: A PRIMARY KEY must include all columns in the table’s partitioning function
Indeed, all tables have a column ID. Maybe you knew how to proceed with this and modify the script if needed.
Thanks for your help.
Sébastien
What Zabbix and MySQL version are you using?
The servers stops collecting data after the MySQL event scheduler are runned. After restarting the server it works again.
Zabbix 5.0.9
MariaDB 10.5.9
DB size ~50GB
When importing the SQL script it it was done in a second. You mentioned that it could take hours on an old installation, do you think there was a problem there?
Try to run partitioning manually and then check the status just like in Step 3.
Thanks,
when running “CALL partition_maintenance_all(‘zabbix’);”, all shows “partitions deleted” as N/A, ie:
+—————-+——————–+
| table | partitions_deleted |
+—————-+——————–+
| zabbix.history | N/A |
+—————-+——————–+
“show create table history\G”:
Table: history
Create Table: CREATE TABLE `history` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT 0,
`value` double(16,4) NOT NULL DEFAULT 0.0000,
`ns` int(11) NOT NULL DEFAULT 0,
KEY `history_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE (`clock`)
(PARTITION `p202103180000` VALUES LESS THAN (1616108400) ENGINE = InnoDB,
PARTITION `p202103190000` VALUES LESS THAN (1616194800) ENGINE = InnoDB,
PARTITION `p202103200000` VALUES LESS THAN (1616281200) ENGINE = InnoDB,
PARTITION `p202103210000` VALUES LESS THAN (1616367600) ENGINE = InnoDB,
PARTITION `p202103220000` VALUES LESS THAN (1616454000) ENGINE = InnoDB)
Is your Zabbix working now? What files do you have in DIR /var/lib/mysql/zabbix ? Did you wait until the 8th day has passed because that is the time when the first partition drop will occur if you configure 7 days for history?
It seems it was a one time glitch that Zabbix stopped collecting data. Now it has been run via the event scheduler a couple of times and all seems good.
Thanks for your help!
So I followed the instructions exact and the verification commands show everything worked, except when I tried to manually run:
mysql -u ‘zabbix’ -p’mypassword’ zabbix -e “CALL partition_maintenance_all”
ERROR 1305 (42000) at line 1: PROCEDURE zabbix.partition_maintenance_all does not exist
So i tried to redo everything and I got:
ERROR 1304 (42000) at line 2: PROCEDURE partition_create already exists
Please help.
Did you use full comand with database like this:
mysql -u ‘zabbix’ -p’zabbixDBpass’ zabbix -e “CALL partition_maintenance_all(‘zabbix’);” ?
got the same error. im running zabbix 5.0 on docker
Hi there,
thanks for the great article.
my question if i have a mysql cluster (2 masters and 1 slave), when and where will/should the scheduled partitioning SQL script run? one master node or all three nodes?
Thanks for your attention.
David
On the master-master cluster, you only need to configure partitioning on one MySQL instance. I m not sure if the same applies to the master-slave cluster.
Thanks. I wonder if a conditional event can be scheduled on both master nodes so that the event will be executed only if the node is associated with a virtual IP? Is that possible? This way a failover will to the other master node would still keep the scheduled event.
The event that is created on the master is disabled by default on the slave. Not sure how that works in the master-master replication environment. In my master-master scenario, I m using crontab on both master nodes and they are running partitioning, one is running on Mon, Wed, Fri, Sun, and the second on is running on Tue, Thu, and Sat.
Is this working? my db still growing.
It should work, keep in mind that you need to wait until the configured threshold for dropping the tables is breached.
For example, if you defined 7 days for history and 365 days for trends partitioning will drop the history table for the first time on the 8th day. After that, it will drop one history table every day so that the database always has historical data for the last 7 days. The same goes for the trend data, only after 365 days partitioning will start to drop trend tables and will always keep 365 days of trend data in the database.
Hi Aldin,
I am seeing a lot of *.ibd file in my server, as you are saying, this files will be drop at the 8th day?
[root@zabbix01 ~]# find . -xdev -type f -size +100M -print | xargs ls -lh | sort -k5,5 -h -r
-rw-r—–. 1 polkitd ssh_keys 2.4G Oct 28 08:01 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history_uint#p#p202010250000.ibd
-rw-r—–. 1 polkitd ssh_keys 2.0G Oct 28 08:45 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history_uint#p#p202010270000.ibd
-rw-r—–. 1 polkitd ssh_keys 1.8G Oct 28 03:52 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history_uint#p#p202010260000.ibd
-rw-r—–. 1 polkitd ssh_keys 1.2G Oct 28 21:32 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history_uint#p#p202010280000.ibd
-rw-r—–. 1 polkitd ssh_keys 1.1G Oct 27 23:35 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000037
-rw-r—–. 1 polkitd ssh_keys 856M Oct 26 15:38 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000030
-rw-r—–. 1 polkitd ssh_keys 833M Oct 28 21:32 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000038
-rw-r—–. 1 polkitd ssh_keys 340M Oct 23 14:41 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000006
-rw-r—–. 1 polkitd ssh_keys 252M Oct 25 17:38 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000020
-rw-r—–. 1 polkitd ssh_keys 215M Oct 26 20:55 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000036
-rw-r—–. 1 polkitd ssh_keys 212M Oct 23 01:08 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000005
-rw-r—–. 1 polkitd ssh_keys 152M Oct 28 08:01 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history#p#p202010250000.ibd
-rw-r—–. 1 polkitd ssh_keys 128M Oct 28 08:45 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history#p#p202010270000.ibd
-rw-r—–. 1 polkitd ssh_keys 128M Oct 23 20:09 ./zabbix-docker/zbx_env/var/lib/mysql/binlog.000017
-rw-r—–. 1 polkitd ssh_keys 116M Oct 28 03:23 ./zabbix-docker/zbx_env/var/lib/mysql/zabbix/history#p#p202010260000.ibd
Yes. Just wait and check on the 8th day. Check your graph for disk usage for the Zabbix DB server.
Hi!
If i list files in /var/lib/mysql/zabbix i see that files created yesterday and today ends with 2300.ibd
Example:
history_uint#P#p202010230000.ibd
history_uint#P#p202010240000.ibd
history_uint#P#p202010250000.ibd
history_uint#P#p202010252300.ibd
history_uint#P#p202010262300.ibd
history_uint#P#p202010272300.ibd
Will this be a problem tomorrow?
I’m not sure why it sometimes sets to 23h instead of 00h but that’s normal – I checked on 3 different Zabbix instances.
Hello.
I’ve done partitioning with your script for 7 d(history) & 365 d(trends) and it works fine.
Could you please answer: what steps should I do if I want to change amount of days for history, for example, 30 days?
Should I just rerun the schema import with history option changed in it?
I have updated the tutorial. Check out step 5.
@ Aldin Osmanagic
Hello, can you plse advise what command i need to run to check if my mysql db is running fine and call partitioning is well implemented.
Rgds
Wizemindz
Use the command from the tutorial:
mysql -u ‘zabbix’ -p’zabbixDBpass’ zabbix -e “show create table history\G”
Everything is working as intended if you receive “PARTITION p0000″ in the output of that command..
Hello,
why not replace crontab with mysql’s event function?
Hello Gu Jin,
That sounds great, we could have a complete configuration in one SQL script with mysql event function. Do you have experience with that? Can you share your configuration/settings?
Regards
Aldin
Hi,
Thanks for publishing your solution for partitioning tables in Zabbix. It’s very informative, though I have a suggestion to improve the solution.
One of the weaknesses of the current solution is that if the partition management fails, then Zabbix will stop collecting data when the last partition is used and a new one is required. In your example of:
CREATE TABLE trends (
itemid bigint(20) unsigned NOT NULL,
clock int(11) NOT NULL DEFAULT ‘0’,
num int(11) NOT NULL DEFAULT ‘0’,
value_min double(16,4) NOT NULL DEFAULT ‘0.0000’,
value_avg double(16,4) NOT NULL DEFAULT ‘0.0000’,
value_max double(16,4) NOT NULL DEFAULT ‘0.0000’,
PRIMARY KEY (itemid,clock)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
/*!50100 PARTITION BY RANGE (clock)
(PARTITION p201910140000 VALUES LESS THAN (1571094000) ENGINE = InnoDB,
PARTITION p201910150000 VALUES LESS THAN (1571180400) ENGINE = InnoDB,
PARTITION p201910160000 VALUES LESS THAN (1571266800) ENGINE = InnoDB) */
any data with a clock value greater than or equal to 1571266800 would error out. To prevent this, the following should be used:
CREATE TABLE trends (
itemid bigint(20) unsigned NOT NULL,
clock int(11) NOT NULL DEFAULT ‘0’,
num int(11) NOT NULL DEFAULT ‘0’,
value_min double(16,4) NOT NULL DEFAULT ‘0.0000’,
value_avg double(16,4) NOT NULL DEFAULT ‘0.0000’,
value_max double(16,4) NOT NULL DEFAULT ‘0.0000’,
PRIMARY KEY (itemid,clock)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
/*!50100 PARTITION BY RANGE (clock)
(PARTITION p201910140000 VALUES LESS THAN (1571094000) ENGINE = InnoDB,
PARTITION p201910150000 VALUES LESS THAN (1571180400) ENGINE = InnoDB,
PARTITION p201910160000 VALUES LESS THAN (1571266800) ENGINE = InnoDB)
PARTITION pMAX VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB) */
The final partition ‘pMAX’ acts as an overflow partition, that will take any data that doesn’t belong to any of the other partitions. Dropping old partitions remains the same, however to add new partitions, you ‘split’ the ‘pMAX’ partition. E.G.:
ALTER TABLE `trends` REORGANIZE PARTITION pMAX INTO
(PARTITION p201910180000 VALUES LESS THAN (1571353200) ENGINE = InnoDB,
PARTITION pMAX VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB);
Another advantage is that you can use Zabbix to monitor for rows in the pMAX partition and alert that partition management is required, before it becomes a major issue, through the following check:
SELECT count(*) from `trends` PARTITION (pMAX);
This should return zero (0) if all is well and non-zero if partition management is required.
I have tested this in MySQL 8.0.21 but the MySQL documentation has this functionality as early as MySQL 5.6.
Thx for the suggestion, I will try to test that in a small Zabbix production before updating the tutorial.
Regards
Hi,
I have just run into the issue above. I have an issue with my crontab, so the new partitions didn’t get created, and I didn’t realise. So I lost a bunch of data 🙁
Do you know when the above update may be implemented?
Thanks
exactly same me. and after running 2 or 3 days will be stop because table does not exit
I updated the tutorial on how to configure the MySQL event function instead of crontab. Regards
could you tell us what should we change in script to apply (pMAX) table ?
This is a great article. Thank you.
I’ve inherited a zabbix environment that I am in the process of upgrading. Our zabbix server is currently at 3.4 and I’m upgrading to 4.4. In the process I am also going to partition the mysql database.
My current setup is zabbix server (mysql) and 5 proxies (4 proxies using mysql; 1 using sqlite3). If I partition the zabbix server database, do I need to do the same for the proxies? I have not been able to find an reference to what should/should not be done with the existing proxy servers.
Thanks in advance.
Hello Jennifer,
No, you do not need to partition the database on the proxy. As a matter of fact, you can even delete that database and create a new one because Zabbix proxy uses a local database only for “buffering” data. Everything from the proxy is sent to the main Zabbix database and proxy pulls configuration from the server regularly.
Just to note something, Zabbix 4.4 is no longer supported and maintained, consider using long term support Zabbix 4.0 or latest 5.0.
Regards
Hi a little question about that, if we have partitioned the database and want to migrate, what is the best approach for that, i’ve read that a backup of the database is recommended for prevention and to be able to recover from a bad upgrade, but i haven’t got any info and how properly backup de database once partitioned, from what i’ve read a logical backup won’t suffice, any feedback on the matter will be very appreciated.
Use mysqldump to backup Zabbix database:
Backup Zabbix database:
mkdir -p /opt/zabbix_backup/db_files
mysqldump -h localhost -u’root’ -p’rootDBpass’ –single-transaction ‘zabbix’ | gzip > /opt/zabbix_backup/db_files/zabbix_backup.sql.gz
Restore Zabbix database:
mysql -u’root’ -p’rootDBpass’ -e “drop database zabbix”
mysql -u’root’ -p’rootDBpass’ -e “create database zabbix character set utf8 collate utf8_bin;”
mysql -u’root’ -p’rootDBpass’ -e “grant all privileges on zabbix.* to zabbix@localhost identified by ‘zabbixDBpass’;”
mysql -u’root’ -p’rootDBpass’ zabbix -e “set global innodb_strict_mode=’OFF’;”
zcat /opt/zabbix_backup/db_files/zabbix_backup.sql.gz | mysql -h localhost -u’root’ -p’rootDBpass’ ‘zabbix’
mysql -u’root’ -p’rootDBpass’ zabbix -e “set global innodb_strict_mode=’ON’;”
After restoration, you need to setup partitioning again.
Thanks for your post, i went through it and worked perfectly for me, i was on SATA 7.2k disks with 400 hosts with 17.5K items enabled 7.5k triggers and 135.56 NVPS, and it got stabled, now i purchased a couple of ssd 2TBs drives to speed things a little bit, but i wonder what method is the best way to backup the database now that has been partitioned and avoid any issues, because i want to migrate the database to a new VM and have the front-end and vm separated.
Thanks for this article, but I would like to hear your opinion on a video by Zabbix, where it’s strongly suggested not to use “stored procedures” any more, but an external Perl script which is offered official(?) by Zabbix itself. What do you think?
The video: https://youtu.be/ANQ3DHTr6eo
The perl script: https://www.zabbix.org/wiki/Docs/howto/mysql_partitioning#Partitioning_with_an_external_script
Hi Macro,
That script is fine, you can use it, but I prefer the KISS principle. With stored procedures, you are eliminating third-party scripts that may or may not work in future Zabbix releases.
Note that Zabbix Wiki is driven by the community, that is not an official recommendation. You have multiple tutorials for DB partitioning on Zabbix Wiki and most of them use stored procedures. Zabbix official documentation doesn’t mention partitioning at all even though they are recommending it on training.
Regards
Thanks for the guide. We implemented this but already have 30 days of history. New history is placed in items moving forward, but our first ‘daily’ partition has 30 days of items. Is there another script we need to run in order to create partitions for older data?
I don’t have a script for that. However, if you have enough storage space, you can wait and after 30 days your first partition, that holds old data, will be dropped.
Regards
Hello,
I don’t understand this.
define days for “data storage period” for trends and history under History and Trends section (must be the same as the days configured in database partitioning);
where I can find ” same as the days configured in database partitioning “?
It should be 7 days for history and 365 days for trends if you have not changed the defaults in the script (Step 1). I have updated this section in the tutorial to make it clearer.
There is syntax error if DB name contain “-” sign.
Thanks for script!
Thx for the info. Yes, MySQL doesn’t like the sign dash “-” in the database name so avoid using it or rename the database.
I only just heard of this partitioning solution. Right now I believe housekeeping is causing us to have false alerts. If i read this correctly, this script creates a different table for each day? Does that mean that for history data, there will be 365 tables?
Hello Jim,
not exactly, history (raw data) will have only 7 tables, but trends (consolidated hourly data) will have 365 tables.
You will have data on graphs for the whole year but you will only have raw data for 7-day which is more than enough.
Regards
hi Aldin,
thanks for such great tool for zabbix! since trends data are much smaller than the history data, can I partition trends data for every month? How can I do that?
Hi,
Your article looks like a great solution.
I have a kinda a big zabbix system that uses this 1000 servers consistently been monitored. Wse AWS RDS MySQL as back-end. The DB now is about 1TB.
– Any thoughts about using this method? I mean do you think is viable for this size have you had any experience in suck an environment?
Regards
Abel
Hi Abel,
I have experience with 600GB installation, and I can tell you that partitioning of such installation can last from 1h up to 24hours depending on disk speed.
Offtopic, 1TB just for 1000 servers? Did you optimize your intervals and reduced history data to a minimum?
Send me an email from the Contact page and we can talk more
Best regards